קצירת נתונים: איך להפוך מידע גולמי לתובנות עסקיות בעזרת Python ו-AI
בעידן הדיגיטלי, איסוף נתונים (Data Scraping) הוא כלי מרכזי לניתוח מידע, חיזוי מגמות וקבלת החלטות מושכלות. Python, בשילוב עם כלי AI ו-Excel, מאפשרת קצירת נתונים ממקורות שונים, עיבודם והסקת מסקנות בצורה אוטומטית ויעילה. מאמר זה יסביר כיצד ניתן לבצע את התהליך החל מאיסוף הנתונים ועד לעיבודם עם בינה מלאכותית, תוך פירוט של טכניקות מתקדמות ותרחישים מעשיים.

שלב 1: קצירת נתונים באמצעות Python
בחירת השיטה הנכונה לקצירת נתונים: כל אתר שונה במבנהו ולכן חשוב להתאים את כלי הקצירה לאופי המידע:
- BeautifulSoup: מתאים לאתרים בעלי מבנה HTML יציב ולא דינמי. פשוט ומהיר ליישום.
- Scrapy: הפתרון המועדף לאתרים גדולים ורב-עמודיים. כולל מערכת מובנית לניהול קישורים, ביצועים גבוהים ותמיכה במאות אלפי עמודים.
- Selenium: חובה באתרים דינמיים (SPA) או במקרים שבהם נדרשת אינטראקציה: קליקים, טעינת נתונים, מילוי טפסים ועוד.
שימוש מתקדם ב-Scrapy לקצירה מאתרים בהיקף גדול
Scrapy היא ספרייה מהירה ועוצמתית המאפשרת לבנות רובוט קצירה מלא (Spider), לנהל קישורים ולהוציא מידע בצורה אוטומטית.
התקנת Scrapy
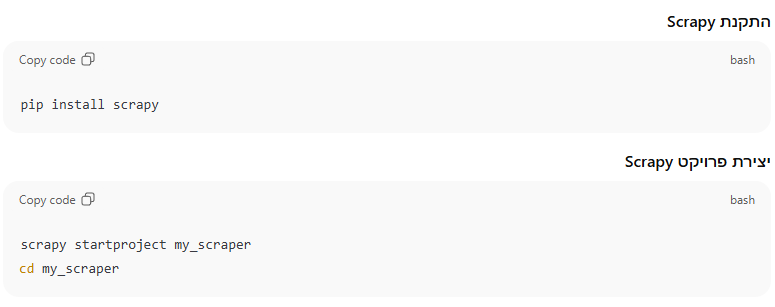
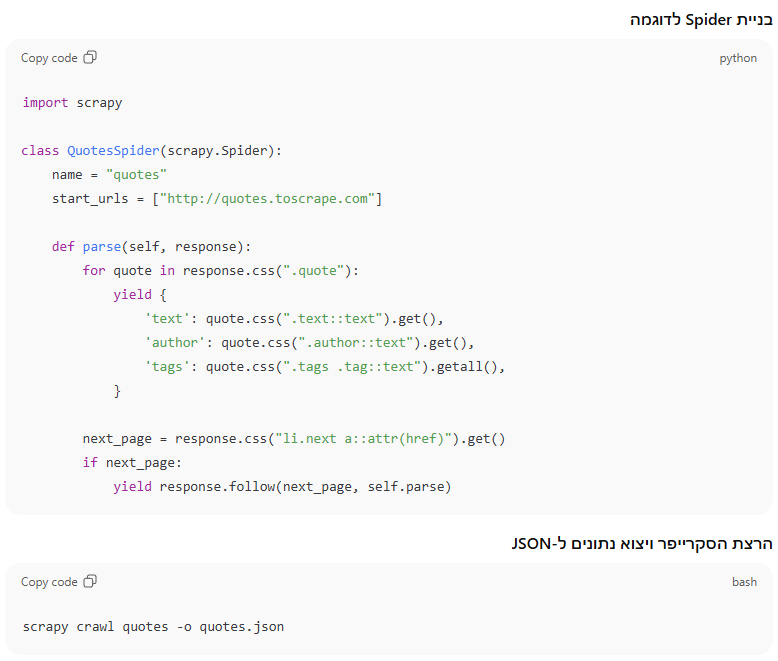
שלב 2: שמירת הנתונים וייבוא ל-Excel
לאחר קצירת הנתונים, מגיע השלב החשוב של ארגון וטיוב המידע. ספריית Pandas מאפשרת לייצר קובצי Excel/CSV, לבצע חישובים, לנקות שדות ולנתח מגמות.
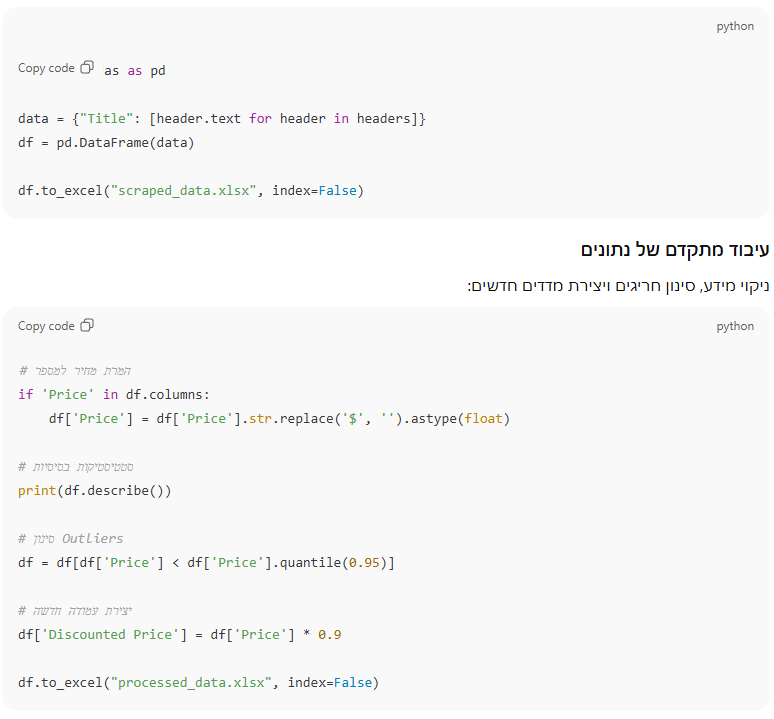
שלב 3: שילוב בינה מלאכותית להסקת מסקנות ולסיווג נתונים
לאחר עיבוד הנתונים, ניתן להפיק מהם תובנות חכמות באמצעות מודלים של למידת מכונה ובינה מלאכותית.
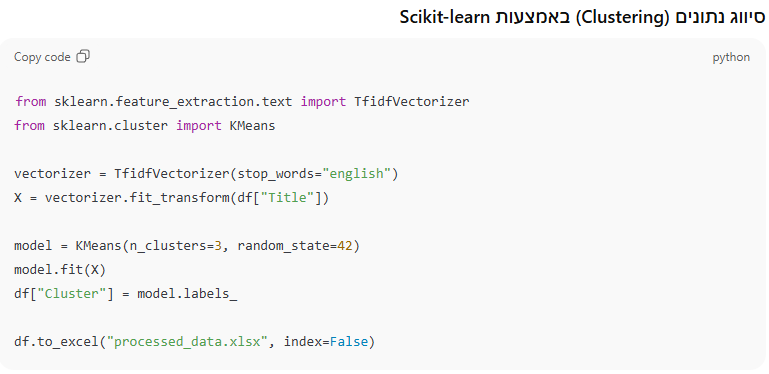

Python היא כלי עוצמתי לקצירת נתונים ממקורות מגוונים. בשילוב עם Excel וכלי AI, ניתן להפוך נתונים גולמיים לתובנות מעמיקות ולהפיק מהם ערך עסקי רב. שימוש בטכניקות למידת מכונה ובינה מלאכותית מאפשר אוטומציה חכמה של תהליכי ניתוח הנתונים, חיסכון בזמן וקבלת החלטות מבוססות מידע. שילוב של BeautifulSoup, Selenium ו-Scikit-learn מאפשר להתמודד עם אתגרים מורכבים בקצירת וניתוח הנתונים, תוך שיפור איכות התובנות העסקיות.